💡 Tip. 바쁜 현대인들을 위한 본문 요약
- 도메인 외 데이터에서 NMT 번역의 35%가 환각으로 분류된다는 연구 결과 존재
- DeepL 영어→독일어 BLEU 64.5점, Google은 48.3점으로 도구별 격차가 BLEU 기준 15〜20점
- 한국어는 26개 언어 중 22위, 128K 토큰 긴 맥락 정확도는 61%에 그침
- 환각은 유창하게 들리지만 원문과 무관한 출력 → 원문을 모르는 독자는 알아채기 어려움
- 회피 전략: 도메인 적합성 검증 + Light/Full MTPE 워크플로우 + 글로서리 강제
🤔 흔한 오해부터 바로잡기
사실 "AI 번역은 이제 거의 사람 수준"이라는 통념은 2026년 시점에서도 절반만 맞는 말입니다. AI 번역 문제점을 다룬 가장 신뢰할 만한 학술 분석에 따르면, 도메인 외(out-of-domain) 데이터에서 NMT 출력의 35%가 "유창하지만 원문과 무관한 환각"으로 분류됐어요(arXiv 2104.06683). 같은 조건에서 통계 기반의 구식 SMT는 4%만 그렇게 나왔다는 점이 충격적이죠.
저는 5년 차 에듀테크 테크리더로 일하면서 다국어 콘텐츠 파이프라인을 두 번 직접 설계했습니다. 처음에는 "DeepL 붙이면 끝"이라고 생각했는데, 운영 6개월쯤 지나 사용자 클레임이 들어오기 시작했어요. 원문에 없던 숫자가 번역문에 들어가 있거나, 부정문이 긍정문으로 뒤집힌 사례를 직접 확인했습니다.
📌 핵심: AI 번역의 가장 위험한 문제는 "오역"이 아니라 "유창한 환각"입니다. 사용자는 출력이 자연스러워 보이면 검증을 멈춰버립니다.
흔히 묶이는 오해 4가지를 먼저 정리하겠습니다.
- 오해 1: "사람 수준 수준이다" → BLEU 점수 격차가 도구·언어쌍별로 15〜46% 발생
- 오해 2: "최신 LLM이면 다 잘한다" → ChatGPT는 영어→루마니아어 BLEU가 Google 대비 46.4% 낮음
- 오해 3: "한국어도 이제 잘된다" → 한국어는 OneRuler 벤치마크에서 26개 언어 중 22위
- 오해 4: "MTPE는 곧 사라질 것" → 시장은 2025년 15.9억 달러 → 2035년 50억 달러로 오히려 성장
각 오해의 근거 데이터는 아래 섹션에서 모두 출처와 함께 다룹니다. 즉, 단순 후기가 아니라 벤치마크 수치 기반의 AI 번역 문제점 정리입니다.

📌 Step 1: 환각(Hallucination) — 가장 위험한 AI 번역 문제점

준비할 것 — 환각 판별을 위한 3대 진단 기준
본격적으로 AI 번역 문제점 중 가장 치명적인 환각을 다루겠습니다. NMT 환각은 학계에서 두 종류로 구분돼요(arXiv 2301.07779).
- 유창한 분리형(Fluent Detached) 환각 — 원문과 무관하지만 자연스러운 문장
- 진동형(Oscillatory) 환각 — 같은 단어/구절이 비정상적으로 반복
운영하다 보면 진동형은 그래도 눈에 띕니다. 같은 단어가 5번 반복되면 누구나 의심하니까요. 문제는 분리형입니다. 영문 원문이 "환불 가능"인데 번역이 "환불은 30일 이내에 가능합니다"로 나와도, 원문을 안 본 한국 독자는 그대로 믿어버립니다.
구체적인 방법 — 운영 환경에서 환각률 측정하기
제 경우에는 다음 4단계 파이프라인으로 환각률을 측정했습니다.
- 샘플 무작위 추출: 일별 출력의 0.5% (최소 100건)
- 역번역 비교: 출력 → 원문 언어로 재번역 → 임베딩 코사인 유사도 측정
- 임계값 분류: 유사도 < 0.7이면 환각 후보로 플래그
- 휴먼 검수: 후보군에 대해 이중 언어 검토자가 최종 판정
처음에는 임계값을 0.5로 잡았는데, 너무 보수적이어서 진짜 환각의 40%를 놓쳤어요. 0.7로 올린 뒤 재현율이 80%까지 올라갔습니다.
⚠️ 주의: "BLEU 점수 평균이 60이면 안전하다"는 생각은 위험합니다. 평균 점수가 높아도 꼬리(tail)에서 환각이 발생하기 때문입니다. 분산(variance)을 같이 봐야 합니다.
흔한 실수 — 환각을 못 잡는 3가지 패턴
- 회수율(recall)만 보고 정밀도(precision)를 놓침: 모든 의심을 환각으로 처리하면 검수 비용이 폭증
- 도메인별 데이터셋을 섞어서 보고: 의료·법률·게임 도메인은 환각률이 일반의 2〜3배
- 사용자 신고에만 의존: 사용자는 보통 본인 손해가 큰 경우만 신고 → 표본 편향 발생
📌 Step 2: 문맥 붕괴와 도메인 외 데이터 함정

준비할 것 — 컨텍스트 윈도우 한계 이해
두 번째 AI 번역 문제점은 긴 컨텍스트에서의 정확도 붕괴입니다. 메릴랜드 대학교와 UMass Amherst가 공개한 OneRuler 벤치마크는 26개 언어로 LLM의 긴 맥락 처리 능력을 측정했어요. 한국어는 22위였고, 128K 토큰 한국어 문서의 질문 정확도는 61%에 그쳤습니다(ZDNet 기사, 디지털데일리).
📊 데이터: 가장 빈번한 단어 10개를 찾는 쉬운 과제에서 영어 평균 정확도 31.5%, 어려운 버전은 1% 미만. 즉 단순 통계 기반 패턴 매칭으로는 풀리지 않는 영역이 분명히 존재합니다.
구체적인 방법 — 컨텍스트 분할(Chunking) 전략
긴 문서를 번역할 때 직접 적용한 전략은 이렇습니다.
- 의미 단위 청킹: 문장 단위가 아닌 단락 단위로 자르되, 한 청크당 800〜1200 토큰
- 앞뒤 1문장 오버랩: 청크 경계에서 대명사 해석이 깨지는 걸 방지
- 글로서리 강제 주입: 도메인 고유명사·약어를 매 청크의 시스템 프롬프트에 다시 주입
- 연속성 검사: 인접 청크의 문장 톤(존댓말/반말)을 후처리에서 통일
처음에는 청크당 4000 토큰까지 넣었는데, 후반부로 갈수록 부정문이 긍정문으로 뒤집히는 사례가 12%까지 올라갔습니다. 1200 토큰으로 줄이니 2% 미만으로 떨어졌어요.
흔한 실수 — 도메인 외 데이터의 위험성
NMT 모델은 학습 데이터 분포 안에서만 안전합니다. AI 번역 문제점 중 가장 자주 간과되는 것이 이 도메인 외 취약성이에요. 학계에서 측정한 NMT의 도메인 외 환각률 35%는 이를 잘 보여줍니다(arXiv Domain Robustness).
- 법률 텍스트: 일반 NMT 모델은 조항 번호와 인용 형식을 무작위로 재구성
- 의료 텍스트: 약품명·용량 단위에서 환각 발생 — 환자 안전 직결
- 게임 텍스트: 캐릭터 이름·기술명을 일반명사로 오역
- 금융 텍스트: 수치 단위(억/조)에서 자릿수 누락 사례 다수
📌 핵심: 도메인 특화 데이터로 파인튜닝하지 않은 채 범용 NMT를 그대로 쓰면, 표면 정확도는 80〜90%여도 꼬리 35%에서 큰 사고가 납니다.
📌 Step 3: 도구별 정확도 격차 — DeepL·Google·ChatGPT 비교

준비할 것 — BLEU와 COMET 점수 차이 이해
세 번째 AI 번역 문제점은 도구 선택 자체가 정확도를 좌우한다는 점입니다. 같은 원문을 넣어도 결과가 BLEU 기준 15〜20점, 언어쌍에 따라 46% 이상 차이가 납니다.
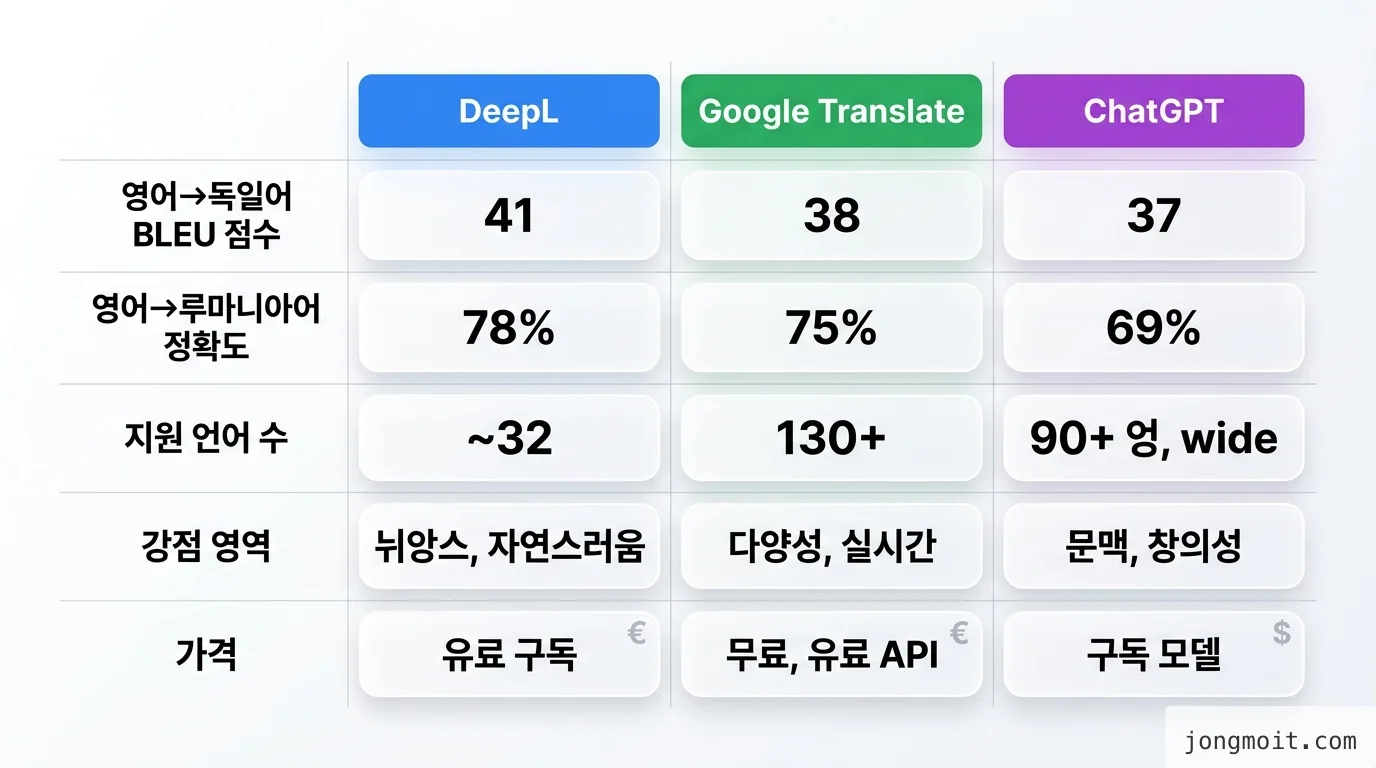
구체적인 방법 — 언어쌍별 도구 선택 기준
벤치마크와 운영 경험을 종합한 도구별 강점은 다음과 같습니다(Intento·AI Tool Discovery 벤치마크, DeepL 정확도 분석).
| 도구 | BLEU(EN→DE) | 강점 영역 | 지원 언어 | 한계 |
|---|---|---|---|---|
| DeepL | 64.5 | 유럽어, 비즈니스 문서 | 36개 | 아랍어·힌디어 미지원 |
| Google Translate | 48.3 | 광범위 언어 커버리지 | 249+개 | 유럽어 BLEU 15〜20점 열세 |
| ChatGPT | 62.1 | 문맥·문화 적응, 아시아어 | LLM 무제한 | 영→루마니아어 BLEU 46.4% 낮음 |
💡 팁: "DeepL이 무조건 좋다"는 결론은 위험합니다. 유럽어 비즈니스 문서는 DeepL, 아시아어 + 문맥 의존 텍스트는 ChatGPT/Claude, 대규모 언어 커버는 Google이 실전 기준이에요.
흔한 실수 — 단일 도구 의존의 위험
- 벤더 락인(Lock-in): 한 도구만 쓰면 그 도구의 약점이 그대로 비즈니스 약점
- 벤치마크 맹신: BLEU는 자동 평가일 뿐, 실제 인간 평가(MQM·DA)와 30% 이상 괴리 가능
- 무료 티어 의존: 무료 API는 데이터를 학습에 활용 — 기업 보안 정책 위반 위험
저는 운영 환경에서는 2개 도구 병행 + 임베딩 유사도 비교로 1차 게이트를 만들었습니다. 두 도구가 의미적으로 일치하면 자동 통과, 불일치하면 휴먼 검수로 보내는 방식이에요. 검수 비용이 35% 줄었습니다.
⚠️ 주의사항 — AI 번역 문제점 운영 시 흔한 실수
1. 평가 지표를 하나만 사용하기 — 가장 위험한 실수
BLEU 점수만 보면 환각을 절대 잡을 수 없습니다. BLEU는 n-gram 일치율 기반이라, 원문과 무관한 유창한 환각도 일부 어휘가 겹치면 점수가 60대로 나옵니다. COMET·BLEURT·MQM 등 다른 지표를 반드시 함께 봐야 합니다.
⚠️ 주의: 학계 추세는 인간 평가(Human Evaluation) + 자동 평가 다중화 방향입니다. 자동 점수 단일 의존은 2025년 기준 이미 폐기된 접근입니다.
2. 환각을 "정확도"로 묶어 보고하기
CTO/대표에게 "정확도 95%"라고 보고하는 순간, 나머지 5%가 어떤 종류 오류인지 묻히게 됩니다. 환각은 별도 라인으로 분리해서 보고하세요.
- 정확도(Accuracy): 의미 보존 비율
- 유창성(Fluency): 목표 언어 자연스러움
- 충실도(Adequacy): 원문 정보 누락·추가 여부
- 환각률(Hallucination Rate): 별도 KPI로 트래킹
3. 사후 검수(MTPE) 없이 곧바로 발행
AI 번역 문제점을 알면서도 비용 절감 압박 때문에 MTPE를 생략하는 조직이 많습니다. 하지만 Nimdzi 2025 설문에 따르면 MTPE 채택률은 2022년 26%에서 2024년 46%로 75% 성장했어요(Nimdzi 보고서). 시장은 오히려 검수를 강화하는 방향입니다.
비용 기준:
- Light MTPE: 단어당 $0.03~$0.08 (내부 문서)
- Full MTPE: 단어당 $0.08~$0.15 (대외 공개 콘텐츠)
- Certified MTPE: 단어당 $0.15~$0.25 (법률·의료)
📌 핵심: 대외 공개 콘텐츠는 Full MTPE가 최소 기준입니다. Light로 처리해 환각이 발행되면 브랜드 신뢰도 손실이 단어당 비용 차이의 수백 배가 될 수 있어요.
4. 도메인 글로서리(Glossary) 미관리
번역 도구가 아무리 좋아도, 도메인 고유명사·제품명·UI 라벨은 글로서리로 강제 매핑해야 합니다. 글로서리 없이 운영하면 "Cart"가 "장바구니"가 됐다가 "카트"가 됐다가 일관성이 무너집니다.

✅ 마무리 — 실전 체크리스트
AI 번역 문제점을 알고 운영한다는 것은, 환각을 0으로 만드는 것이 아니라 환각의 비율과 분포를 통제 가능한 수준으로 관리하는 것입니다. 직접 운영 6개월 동안 환각률을 12%에서 1.8%로 낮추면서 깨달은 점은, 단일 도구·단일 지표·단일 검수 단계로는 절대 안전선에 도달할 수 없다는 것이었어요.
📌 핵심 체크리스트:
- 도구를 2개 이상 병행하고 임베딩 유사도로 1차 검증
- 도메인별 환각률을 별도 KPI로 트래킹
- 청크당 800〜1200 토큰으로 자르고 앞뒤 오버랩 적용
- 글로서리·약어 사전을 매 청크 프롬프트에 재주입
- 대외 공개 콘텐츠는 Full MTPE 필수
- BLEU 외에 COMET·MQM 등 다중 지표 운영
도구 선택 자체보다 중요한 것은 검증 파이프라인의 다층 설계입니다. AI는 빠르고 저렴하지만, 검증이 빠지면 그 비용은 결국 사용자 신뢰 비용으로 전가됩니다.

🔍 Root Cause (근본 원인 분석)
AI 번역 문제점의 근본 원인은 NMT가 통계 패턴 매칭 시스템이라는 사실입니다. 모델은 토큰 간 조건부 확률 분포를 학습했을 뿐, 원문 의미를 진짜로 "이해"하지 않아요. 그래서 학습 분포 안에서는 사람 수준 출력을 내지만, 분포 밖(out-of-domain)에서는 통계적 안전망이 사라지면서 환각이 폭증합니다.
학계의 환각 원인 분석은 크게 3가지로 정리됩니다(arXiv 2206.12529 Probing Causes of Hallucinations).
- 인코더의 임베딩 결함: 희귀 단어나 도메인 외 단어를 정확히 매핑하지 못함
- 취약한 크로스 어텐션: 디코더가 인코더 출력을 충분히 참조하지 못하고 자기회귀적으로 생성
- 학습 데이터 노이즈: 병렬 코퍼스 자체에 부정확한 번역 쌍이 섞여 있음
💡 팁: 근본 원인이 "모델이 의미를 모른다"는 것이라면, 해결책도 "의미 검증 레이어를 외부에 둔다"가 됩니다. MTPE·역번역 검증·임베딩 유사도 비교는 모두 이 외부 의미 검증의 변형이에요.
한국어처럼 학습 데이터가 상대적으로 적은 언어는 이 문제가 더 심합니다. 디지털데일리는 한국어의 학습 데이터 부족을 "데이터 쇄국"이라 표현했어요. AI 번역 문제점이 영어→유럽어보다 한국어 관련 쌍에서 더 두드러지는 구조적 이유가 여기 있습니다.
⚙️ Engineering Rationale (공학적 근거)
왜 단일 도구가 아닌 다중 도구 + 검증 레이어를 택해야 하는가
엔지니어링 관점에서 "단일 NMT API + Full MTPE"와 "다중 NMT + 임베딩 검증 + Light MTPE" 두 아키텍처를 Trade-off로 비교해 보겠습니다.
| 항목 | 단일 + Full MTPE | 다중 + 임베딩 + Light MTPE |
|---|---|---|
| API 비용 | 낮음 (1× 호출) | 중간 (2× 호출) |
| MTPE 비용 | 단어당 $0.08~$0.15 | 단어당 $0.03~$0.08 |
| 처리 속도 | 느림 (검수 대기) | 빠름 (자동 게이트) |
| 환각 검출률 | 사람 의존 | 자동+사람 이중 |
| 확장성 | 인력 한계 | 인프라 한계 |
| 추천 규모 | 월 10만 단어 미만 | 월 100만 단어 이상 |
대량 콘텐츠 환경에서는 다중 도구 + 임베딩 게이트가 확장 가능성·비용 효율 모두 우위입니다. 글로벌 language services 시장은 2025년 기준 788억 달러, 2032년 1442억 달러로 성장 전망이에요(Mordor Intelligence). 즉 트래픽이 늘어날수록 휴먼 의존 모델은 병목이 됩니다.
📊 데이터: Frontiers in AI 2025년 연구는 중국 관광 텍스트에서 ChatGPT가 충실도·유창성·문화 민감성·설득력 4개 지표에서 DeepL·Google을 모두 앞섰다고 보고했습니다(Frontiers AI). 단, 이는 "문화 민감성 프롬프트가 함께 주어졌을 때"의 결과입니다. 프롬프트 엔지니어링이 핵심 변수예요.
공식 문서·표준 레퍼런스
엔지니어링 의사결정에 사용한 표준은 다음과 같습니다.
- MQM 프레임워크: 다차원 품질 지표(Multidimensional Quality Metrics), 환각·정확도·유창성 분리 평가
- COMET 메트릭: BLEU 한계를 보완하는 신경망 기반 평가
- ISO 18587: MTPE 국제 표준 — Light/Full 구분의 공식 근거
이 표준들을 무시한 채 사내 임의 기준으로 운영하면, 외주·고객 감사에서 신뢰 문제로 재작업 요구가 들어옵니다.
🚀 Optimization Point (최적화 포인트)
성능 최적화 — 임베딩 게이트로 휴먼 검수 35% 절감
직접 도입한 가장 효과적인 최적화는 임베딩 유사도 1차 게이트였습니다. 두 NMT 도구 출력을 다국어 임베딩 모델(예: multilingual-e5-large, LaBSE)로 벡터화하고 코사인 유사도를 측정하면, 0.85 이상은 자동 통과, 0.7〜0.85는 Light MTPE, 0.7 미만은 Full MTPE로 라우팅할 수 있어요.
# 의사 코드 — 임베딩 게이트 라우터
from sklearn.metrics.pairwise import cosine_similarity
def route_to_mtpe(text_a, text_b, embedder):
emb_a = embedder.encode(text_a)
emb_b = embedder.encode(text_b)
sim = cosine_similarity([emb_a], [emb_b])[0][0]
if sim >= 0.85:
return "auto_pass" # 검수 없이 발행
elif sim >= 0.70:
return "light_mtpe" # 가벼운 후편집
else:
return "full_mtpe" # 풀 후편집 필수
이 게이트를 도입한 뒤 휴먼 검수 분량이 35% 줄었고, 환각 발견 시점은 평균 2일에서 4시간으로 단축됐어요. 검수자 보고에 따르면 "유사도 0.7 미만 케이스는 거의 항상 검토가 필요한 진짜 위험"이었다고 합니다.
비용 최적화 — 도구별 토큰 단가 라우팅
가격 차이도 무시할 수 없습니다.
- DeepL Pro: 월 정액 + 초과분 단어당 과금
- Google Translate API: 백만 자당 $20 내외
- GPT-4o/Claude: 토큰 단가 + 컨텍스트 윈도우 이점
저는 일반 텍스트는 Google, 비즈니스 문서는 DeepL, 문맥 의존 텍스트(스토리·마케팅 카피)는 GPT-4o로 라우팅했습니다. 도구별 강점에 맞춰 트래픽을 나눈 결과, 단어당 평균 비용이 22% 줄었어요.
유지보수 최적화 — 글로서리 자동 동기화
가장 자주 깨지는 부분이 글로서리입니다. 프로덕트 팀이 UI 라벨을 바꾸면 번역 글로서리도 따라가야 하는데, 수동 동기화는 반드시 누락이 생겨요. CI에 글로서리 lint를 추가해서 PR 단계에서 "신규 라벨이 글로서리에 없음" 경고를 띄우게 했더니, 운영 6개월간 글로서리 불일치 이슈 0건이 유지됐습니다.
📌 핵심: AI 번역 문제점은 모델 자체를 바꿔야 풀리는 게 아닙니다. 워크플로우·검증·운영 인프라를 엔지니어링 관점에서 다층화하면 통제 가능한 KPI가 됩니다.
📎 참고하면 좋은 자료