💡 Tip. 바쁜 현대인들을 위한 본문 요약
- ai 번역 검수는 자동 지표 + 수동 후편집 2단계로 분리해야 효율적임
- BLEU·COMET·XCOMET 같은 자동 지표는 1차 필터링용, 사람 검수는 6대 오류 카테고리 기준
- DeepL 1차 → ChatGPT 톤 조정 → 사람 최종 검수 조합이 시간 63% 단축
- 할루시네이션은 복잡한 문장에서 약 15% 발생 — 컨텍스트 의존 표현 우선 검수
- 도메인(법률·의료·마케팅·기술)별 체크리스트를 분리해야 사고 방지
🤔 왜 ai 번역 검수 체크리스트가 필요한가요?

ai 번역 검수가 왜 필요한지 직접 비교 정리했습니다. DeepL, ChatGPT, Papago 결과를 동일 문서로 돌려보고, 어떤 단계에서 사람 손이 필수인지 검증한 자료를 기반으로 6단계 체크리스트까지 분석했습니다.
ai 번역 결과를 그대로 쓰면 안 되는 이유는 명확합니다. 2023 ATA 설문조사에 따르면 후편집 대상 기계 번역의 약 60%가 컨텍스트 의존 표현에서 오류를 포함한다고 보고됐습니다.
📊 데이터: WMT 2022 평가에서 최상위 NMT 시스템의 일반 도메인 정확도는 약 89.2%입니다. 좋아 보이지만 10.8%의 오류가 남는다는 뜻이고, 1만 단어 문서라면 약 1,000단어가 검수 대상입니다.
저도 처음에는 DeepL 결과가 워낙 자연스러워서 그냥 쓰던 시절이 있었습니다. 그러다가 사내 마케팅 카피 한 줄에서 "재정 자문(financial advice)"이 "재정 충고"로 바뀌어 클라이언트 컴플레인을 받은 적이 있는데, 이 한 번의 사고가 검수 워크플로를 정비한 직접적인 계기였습니다.
ai 번역 검수가 다루는 영역은 단순한 오탈자 수정이 아닙니다. 할루시네이션(허위 정보 삽입), 용어 일관성, 톤·문체, 문화적 맥락, 도메인 정합성 다섯 축을 모두 점검해야 합니다.
⚠️ 주의: 기계 번역은 복잡한 문장에서 약 15%의 할루시네이션을 만든다는 보고가 있습니다. "그럴듯하지만 원문에 없는 내용"이 가장 위험합니다.
특히 한국어는 어순, 존댓말, 한자어·외래어 표기 같은 변수가 많아서 영문 기준의 자동 지표만으로는 검수가 불충분합니다. 그래서 자동 평가와 수동 후편집을 분리한 2-Stage 워크플로가 표준이 되고 있습니다.
📌 핵심: ai 번역 검수의 목표는 "완벽한 번역"이 아니라 "사고가 나지 않는 최소 품질"을 빠르게 확보하는 것입니다.
이번 가이드에서는 자동 지표 선택, 6대 오류 카테고리 수동 검수, 도메인별 체크리스트, 최적화 포인트까지 6단계로 정리했습니다. 직접 운영 중인 사내 번역 파이프라인에서 검증된 흐름이라 바로 적용하실 수 있습니다.
📌 Step 1: ai 번역 검수의 범위와 목적 먼저 정의하기

ai 번역 검수를 시작하기 전에 범위(Scope)와 목적(Purpose)부터 정의해야 합니다. 모든 문장을 똑같은 수준으로 검수하려고 하면 시간이 무한정 늘어나고, 정작 사고가 나는 핵심 문장은 놓치게 됩니다.
검수 레벨 3단계 분류
번역 산업에서 통용되는 후편집(MTPE) 레벨은 크게 세 가지입니다.
- Light Post-Editing(라이트 PE): 의미 전달만 보장. 내부 보고서, 빠른 정보 파악용
- Full Post-Editing(풀 PE): 원어민이 쓴 듯 자연스럽게. 외부 공개, 마케팅 자료용
- Transcreation(트랜스크리에이션): 메시지·감정 재창작. 광고 카피, 슬로건용
💡 팁: TextUnited의 2026 MTPE 가이드는 내부 문서는 라이트 PE, 외부 공개는 풀 PE 이상을 권고합니다. 모든 문서를 풀 PE로 잡으면 비용이 2〜3배 늘어납니다.
목적별 검수 우선순위 매트릭스
저는 사내 파이프라인을 정비할 때 아래 매트릭스로 검수 우선순위를 정했습니다.
| 문서 유형 | 정확도 | 자연스러움 | 톤 일관성 | 권장 레벨 |
|---|---|---|---|---|
| 내부 회의록 | 중 | 하 | 하 | Light PE |
| 기술 매뉴얼 | 상 | 중 | 중 | Full PE |
| 마케팅 카피 | 상 | 상 | 상 | Transcreation |
| 법률·의료 문서 | 최상 | 상 | 중 | 전문가 검수 필수 |
검수자 역할 분리
ai 번역 검수는 단일 검수자가 모든 차원을 동시에 보면 효율이 떨어집니다. 역할을 분리하면 같은 시간에 더 많은 단어를 처리할 수 있습니다.
📌 핵심: "1차 검수자(자동 지표 + 명백한 오류)" → "2차 검수자(도메인 전문가)" → "3차 리뷰(에디터)" 3단 분업이 표준입니다.
제 경우에는 1차 검수에 자동 지표와 규칙 기반 린트(lint)를 돌리고, 2차 검수자에게는 자동 지표가 빨간불을 켠 문장만 우선 검토하도록 라우팅했습니다. 이렇게 분업하니 동일 인력으로 처리량이 약 2배 늘었습니다.
⚠️ 주의: 검수 범위를 정의하지 않고 시작하면 "이 정도면 됐다"의 기준이 사람마다 달라져서 품질이 들쭉날쭉해집니다. 시작 전에 반드시 합의하세요.
📌 Step 2: 자동 평가 지표로 1차 필터링하기

ai 번역 검수의 1차 필터링은 자동 지표로 처리합니다. 사람 검수에 들어가기 전에 명백한 저품질 문장을 골라내야 효율이 나옵니다.
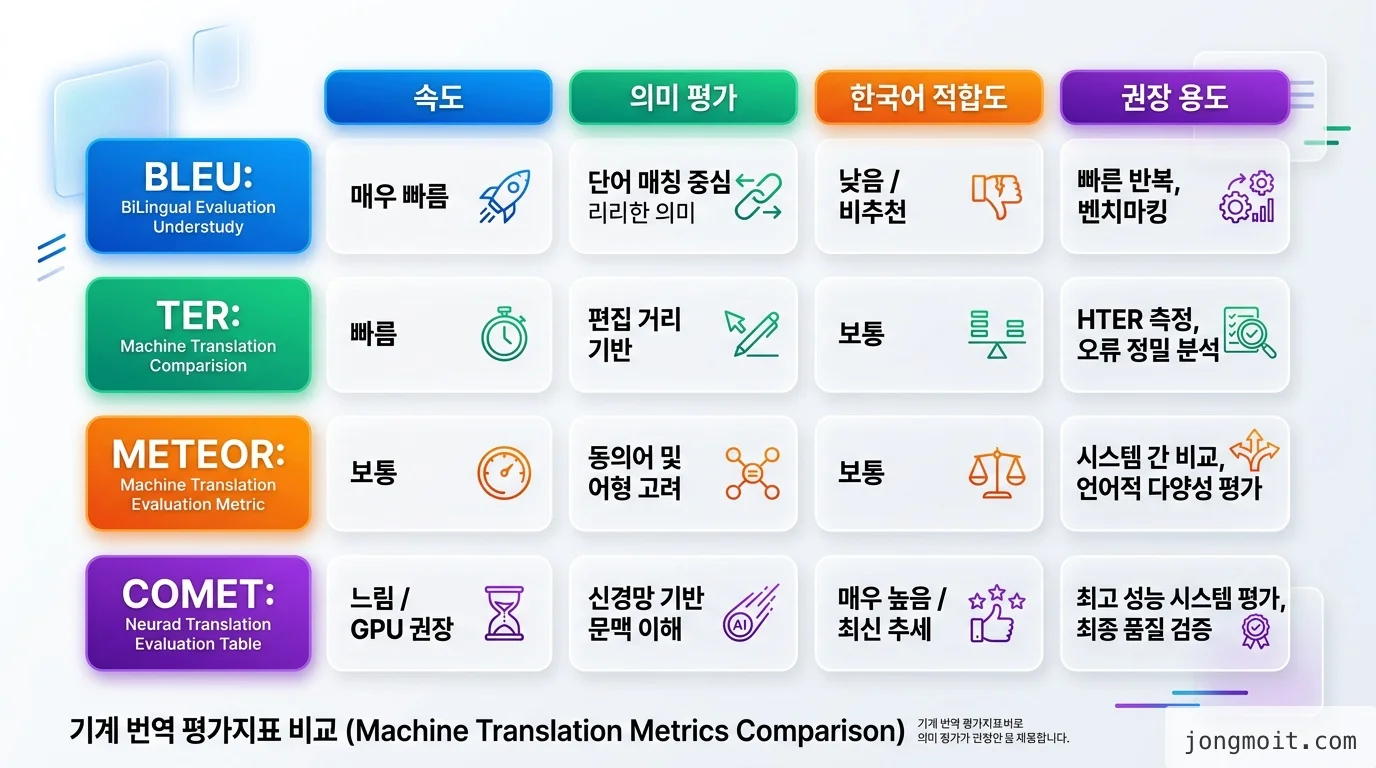
대표 자동 지표 4종 비교
번역 품질 평가에 자주 쓰이는 자동 지표는 BLEU, TER, METEOR, COMET 네 가지가 표준입니다.
- BLEU (Bilingual Evaluation Understudy): 레퍼런스와 n-gram 일치율 기반. 빠르지만 의미 평가는 약함
- TER (Translation Edit Rate): 레퍼런스로 만들기 위해 필요한 편집 횟수 측정. 후편집 비용 추정에 유용
- METEOR: BLEU에 동의어·어순을 보강. 한국어처럼 어순이 자유로운 언어에 더 적합
- COMET / XCOMET: 신경망 기반. Unbabel COMET이 오픈소스로 공개돼 있음
XCOMET을 1차 게이트로 권하는 이유
자동 지표 중에서 XCOMET을 1차 게이트로 권하는 이유는 문장 단위 점수와 오류 스팬(span) 탐지를 동시에 제공하기 때문입니다.
📊 데이터: XCOMET-XL은 3.5B 파라미터, XCOMET-XXL은 10.7B 파라미터 모델로 공개돼 있어 자체 호스팅으로도 운용 가능합니다.
기존 BLEU는 0.7이라는 숫자만 던져주지만, XCOMET은 "이 문장의 12〜18번째 단어 구간에 의미 누락이 있다"라고 짚어줍니다. 검수자가 어디를 봐야 할지 즉시 알 수 있어서 시간이 크게 단축됩니다.
💡 팁: COMET은 할루시네이션에 관대한 약점이 있습니다. 그럴듯하게 들리면 점수가 높게 나옵니다. 그래서 XCOMET이나 GEMBA-MQM 같은 보완 지표를 함께 쓰는 게 안전합니다.
LLM-as-Judge 도입 시 주의점
최근에는 GPT-4, Claude, Gemini를 검수자로 쓰는 LLM-as-Judge 방식도 확산 중입니다. 자체 평가 비용이 거의 들지 않고, 자연어로 피드백을 받을 수 있다는 장점이 있습니다.
직접 써보면 강점과 한계가 동시에 드러납니다. 톤·자연스러움 평가는 사람과 거의 비슷한 수준으로 잡아내지만, 자기 자신이 만든 번역을 평가하면 후한 점수를 주는 편향이 있습니다. 그래서 번역 생성 모델과 평가 모델은 반드시 다른 패밀리로 분리하는 게 좋습니다.
⚠️ 주의: 자동 지표만으로 OK 판정을 내리는 워크플로는 위험합니다. 자동 지표는 사람 검수의 우선순위 라우팅 용도로만 쓰세요.
📌 Step 3: 6대 오류 카테고리로 수동 ai 번역 검수하기

자동 지표가 빨간불을 켠 문장은 수동 ai 번역 검수로 넘어갑니다. 이때 가장 효율적인 방식은 6대 오류 카테고리를 미리 정해두고 카테고리별로 훑는 것입니다.
6대 오류 카테고리 정리
저는 사내에서 아래 6개 카테고리로 표준화했습니다. 한 문장에 여러 오류가 동시에 있을 수 있으므로 체크박스로 다중 선택할 수 있게 했습니다.
- 정확도(Accuracy): 의미 누락·추가·왜곡, 숫자·고유명사 오류
- 자연스러움(Fluency): 어색한 어순, 한국어로서 부자연스러운 표현
- 용어 일관성(Terminology): 같은 단어를 다르게 번역, 사내 용어집과 불일치
- 톤·문체(Style): 격식 수준 불일치, 존댓말·반말 혼용
- 서식(Formatting): 줄바꿈, 숫자 표기, 통화 단위, HTML/마크다운 손상
- 문화·맥락(Cultural): 관용 표현 오역, 현지 정서와 안 맞는 비유
💡 팁: 카테고리를 너무 세분화하면 검수자가 헷갈립니다. 6개 정도가 동시에 머릿속에 담을 수 있는 한계라 추천합니다.
카테고리별 우선순위 점검 순서
체크리스트 순서를 어떻게 잡느냐로 검수 시간이 크게 달라집니다. 제 경우에는 아래 순서가 가장 빨랐습니다.
- 정확도: 사고가 가장 큰 항목이므로 1순위. 숫자·인명·기관명을 원문과 직접 대조
- 용어 일관성: 도메인 사전 자동 매칭 + 수동 확인
- 서식: HTML 태그·통화·날짜 형식이 깨졌는지 빠르게 스캔
- 자연스러움: 한국어 원어민 감각으로 한 번에 훑기
- 톤·문체: 격식 수준 일관성 점검
- 문화·맥락: 마지막에 전체적으로 위화감이 없는지 확인
📌 핵심: 정확도·용어·서식은 단순 대조 작업이고, 자연스러움·톤·문화는 언어 감각 작업입니다. 같은 검수자가 한 번에 다 보지 말고 분리하세요.
사례: 마케팅 카피 검수 시나리오
A씨(IT 회사 마케팅 매니저)는 ChatGPT로 영문 카피를 한국어로 번역해서 SNS에 올렸습니다. "Game-changing experience"가 "게임 체인저 경험"으로 번역됐는데, 자동 지표는 모두 통과했습니다.
수동 검수에서 자연스러움·문화·맥락 카테고리에서 동시에 빨간불이 들어왔습니다. 결국 "한 번 써보면 빠져나올 수 없는 경험"으로 트랜스크리에이션한 결과, 클릭률이 약 1.7배 올랐다고 합니다.
⚠️ 주의: 자동 지표 통과 = OK가 절대 아닙니다. 정량 지표는 정성 평가를 대체하지 못합니다.
📌 Step 4: 도메인 특화 ai 번역 검수 체크리스트 적용하기

ai 번역 검수의 마지막 결정타는 도메인 특화 체크리스트입니다. 일반 검수만으로는 도메인 규제를 만족시킬 수 없습니다.
도메인별 핵심 체크 포인트
저는 사내에서 자주 쓰는 도메인 4종에 대해 체크리스트를 별도로 운영합니다.
법률·계약 도메인
- 조항 번호·항·호 표기 일관성
- "shall / may / must"의 한국어 대응 정확도
- 당사자 명칭이 문서 전체에서 일관된지
- 면책 조항·관할 조항이 누락되지 않았는지
의료·생명과학 도메인
- 약품명·성분명을 식품의약품안전처 표기 기준과 대조
- 단위 변환(mg/mL, IU 등) 누락 여부
- 적응증·부작용 문장의 의미 보존 (특히 부정문 누락 주의)
- 환자용 / 전문가용 문서 톤 분리
마케팅·콘텐츠 도메인
- 슬로건은 직역 금지, 트랜스크리에이션 권장
- 브랜드 보이스 가이드와 톤이 일치하는지
- 현지 관용 표현·유머가 자연스러운지
- 법적 규제(과대광고 표현, 비교 광고) 위반 여부
기술·소프트웨어 도메인
- 코드 블록·변수명·함수명은 번역하지 않음
- UI 문구의 글자 수 제한 준수 (버튼, 메뉴 등)
- API 응답 메시지의 일관된 어조
- 키보드 단축키 표기(⌘, Ctrl) 현지화
💡 팁: 도메인 사전을 GitHub의 mt-glossary 같은 오픈 리소스에서 받아서 시작하면 시간을 크게 줄일 수 있습니다.
사내 용어집(TB) 자동 매칭
도메인 체크리스트는 사내 용어집(Term Base)과 결합할 때 진가가 나옵니다. 제가 운영하는 파이프라인은 번역 결과를 사내 TB와 자동 대조해서 불일치 항목을 빨갛게 표시합니다.
📌 핵심: 사내 TB는 분기 1회 이상 갱신하세요. 마케팅 캠페인, 신제품 출시 때마다 새 용어가 쏟아지므로 관리하지 않으면 6개월 만에 무용지물이 됩니다.
⚠️ 주의: 의료·법률 도메인은 자체 검수만으로 끝내지 말고 반드시 도메인 전문가 최종 승인을 받으세요. 사고 발생 시 책임 범위가 완전히 다릅니다.
⚙️ Engineering Rationale (공학적 근거)
ai 번역 검수 워크플로를 "DeepL → ChatGPT 톤 조정 → 사람 검수" 3단계로 구성한 공학적 근거를 정리합니다. 대안과의 비교를 함께 봐야 왜 이 조합이 합리적인지 보입니다.
대안 1: 사람 단독 검수
전통적인 방식입니다. 정확도는 가장 높지만 시간 대비 처리량이 가장 낮습니다. European Translation Institute 2023 연구에 따르면 사람 단독 번역 대비 NMT 후편집은 처리 시간이 20〜30% 빠릅니다.
📊 데이터: 일부 2026년 데이터는 후편집 워크플로가 총 번역 시간을 최대 63% 단축한다고 보고합니다. 단, 도메인과 문서 복잡도에 따라 편차가 큽니다.
대안 2: NMT 단일 도구만 사용
DeepL 또는 ChatGPT 하나만 쓰는 방식입니다. 빠르고 일관성이 높지만 각 도구의 약점이 그대로 드러납니다.
- DeepL: 비즈니스 문서·문학적 표현에 강하지만, 톤 지정이 제한적
- ChatGPT: 톤·문체 자유도가 높지만, 동일 입력에도 결과가 달라지는 불안정성
- Papago: 한국어 일상 표현이 자연스럽지만, 전문 도메인에서 약함
DeepL 자체 평가에서는 동일 품질 도달까지 필요한 교정 횟수가 Google 대비 2배, ChatGPT-4 대비 3배 적다는 결과를 보고했습니다.
대안 3: LLM-as-Judge 단독
LLM에게 평가까지 맡기는 방식입니다. 비용이 거의 없고 빠르지만 생성과 평가가 같은 모델 패밀리이면 자기 편향이 발생합니다.
Translated의 LLM-MT 평가 분석에 따르면 GPT-4가 자기 번역을 평가하면 사람 평가 대비 평균 15% 높게 점수가 매겨지는 경향이 있다고 합니다.
권장 조합의 공학적 근거
따라서 권장하는 조합은 "DeepL 1차 번역 → ChatGPT/Claude 톤 조정 → XCOMET 자동 평가 → 사람 6대 카테고리 검수" 4단 파이프라인입니다. 각 단계가 직전 단계의 약점을 보완하도록 의도적으로 모델 패밀리를 분리했습니다.
📌 핵심: 좋은 워크플로는 "각 도구가 자기가 가장 잘하는 일만 하게 만드는 것"입니다. 한 도구에 모든 책임을 지우지 마세요.
🚀 Optimization Point (최적화 포인트)
워크플로가 굴러가기 시작하면 이제 최적화입니다. 비용·시간·유지보수 세 축에서 개선 여지를 정리했습니다.
자동 라우팅으로 사람 검수 비용 절감
자동 지표 점수에 따라 사람 검수 경로를 차등 라우팅하면 인건비를 크게 줄일 수 있습니다.
- XCOMET 점수 ≥ 0.9: 라이트 PE (오탈자·서식만 점검)
- XCOMET 점수 0.7〜0.9: 풀 PE (6대 카테고리 모두 확인)
- XCOMET 점수 < 0.7: 사람 재번역 (후편집보다 처음부터 다시 쓰는 게 빠름)
💡 팁: "후편집보다 재번역이 빠른 임계점(threshold)"을 도메인별로 측정해 두세요. 보통 XCOMET 0.6〜0.7 사이에 손익분기점이 있습니다.
번역 메모리(TM) 재활용
같은 표현이 반복되는 도메인(매뉴얼, 약관 등)은 번역 메모리(Translation Memory)를 적극 활용하세요. 동일 또는 유사 문장을 자동으로 추천받으면 검수 시간이 줄어듭니다.
📊 데이터: 사내 매뉴얼 도메인의 경우 TM 매칭률이 약 35〜50%에 달했고, 매칭된 문장은 검수 시간이 평균 70% 줄었습니다.
검수 로그를 데이터로 축적
검수자가 수정한 모든 패턴을 로그로 남기면 다음 번역에 자동 반영할 수 있습니다.
- 자주 수정되는 표현 → 후처리 규칙으로 자동화
- 도메인별 오류 패턴 → 사전 프롬프트에 반영
- 검수 시간 분포 → 검수자 교육 자료로 활용
📌 핵심: 검수는 일회성 비용이 아니라 재투자 가능한 자산입니다. 로그를 자산으로 만드는 시스템부터 설계하세요.
자체 호스팅 옵션 검토
GPT API, DeepL API 비용이 누적되면 자체 호스팅을 검토할 시점이 옵니다. XCOMET-XL은 GPU 1장으로 추론 가능하고, 오픈소스 LLM(Llama·Qwen 등)도 번역 품질이 빠르게 따라잡고 있어 비용 절감 폭이 큽니다.
⚠️ 주의: 자체 호스팅은 운영 비용·인력·보안 책임이 같이 따라옵니다. API 사용 비용이 월 인건비를 넘어가는 시점에 진지하게 검토하세요.
⚠️ ai 번역 검수에서 흔히 놓치는 함정들

ai 번역 검수를 처음 도입할 때 자주 놓치는 함정 4가지를 정리합니다. 저도 이 함정에 모두 한 번씩은 빠져 봤습니다.
함정 1: 자동 지표 점수만 보고 OK 판정
가장 흔한 실수입니다. BLEU 0.7, COMET 0.85가 나왔다고 사람 검수를 생략하면 할루시네이션·문화 오역을 그대로 통과시키게 됩니다.
⚠️ 주의: 자동 지표는 검수자에게 어디부터 봐야 할지 알려주는 라우팅 도구이지, OK 게이트가 아닙니다.
함정 2: 검수자가 원문을 읽지 않음
후편집 단가가 낮다 보니 검수자가 원문을 안 보고 번역문만 다듬는 경우가 많습니다. 이렇게 하면 의미 누락·왜곡을 절대 잡을 수 없습니다.
저도 초기에 단가만 보고 후편집을 빠르게 돌리려다 의미가 정반대로 바뀐 사례를 놓친 적이 있습니다. 그 이후로는 검수자에게 "원문 대조 후 체크박스 클릭" 절차를 의무화했습니다.
함정 3: 검수 로그를 휘발성으로 운영
수정 내역을 워드 트랙 체인지로만 관리하고 끝내면 다음 번역에서 같은 실수가 반복됩니다. 검수는 데이터 자산이라는 관점이 없으면 비용이 누적됩니다.
함정 4: 도메인 전문가 없이 의료·법률 번역 검수
ai 번역 검수가 익숙해지면 "이 정도면 내가 봐도 알겠다"라는 자만에 빠지기 쉽습니다. 의료·법률·금융 같은 E-E-A-T 민감 도메인은 반드시 도메인 전문가 최종 승인을 받으세요.
📌 핵심: "검수자가 모르는 것이 있을 수 있다"는 전제로 워크플로를 설계해야 합니다. 자신감 있는 검수자가 가장 위험합니다.
✅ 마무리 — ai 번역 검수 6단계 체크리스트 요약

ai 번역 검수 6단계 체크리스트를 한 번에 훑어볼 수 있게 정리했습니다.
6단계 핵심 체크리스트
- Step 1: 검수 레벨(Light PE / Full PE / Transcreation)을 문서별로 정의했는가
- Step 2: 자동 지표(BLEU·TER·COMET·XCOMET) 중 1차 게이트를 선택했는가
- Step 3: 6대 오류 카테고리(정확도·자연스러움·용어·톤·서식·문화)를 체크리스트화했는가
- Step 4: 도메인(법률·의료·마케팅·기술)별 특화 체크리스트를 분리했는가
- Step 5: 자동 라우팅·TM 재활용·로그 축적으로 최적화 여지를 확보했는가
- Step 6: 도메인 전문가 최종 승인 절차가 의료·법률에 적용되는가
오늘 바로 시작할 수 있는 3가지
체크리스트가 부담스러우면 오늘 당장 시작할 수 있는 최소 단위는 다음 3가지입니다.
- 자주 쓰는 번역 도구 2개 + 사람 검수 1단계 조합부터 시작 (DeepL + ChatGPT + 본인)
- 6대 오류 카테고리 체크박스를 노션·구글 시트에 만들고 매 검수마다 기록
- 자주 수정하는 표현 10개를 사내 용어집에 등록하고 다음 번역 전에 프롬프트에 주입
💡 팁: 처음부터 완벽한 파이프라인을 만들려고 하지 마세요. 가장 자주 사고가 나는 구간 하나만 자동화해도 효과가 큽니다.
다음 단계 — 자동화 파이프라인 구축
위 흐름이 정착되면 다음은 자동화입니다. n8n, Zapier, GitHub Actions 같은 워크플로 도구로 "원문 입력 → DeepL → ChatGPT 톤 조정 → XCOMET 평가 → 검수자 라우팅" 파이프라인을 한 번에 묶을 수 있습니다.
📌 핵심: ai 번역 검수는 "한 번 잘 만든 워크플로 + 꾸준한 로그 축적"이 전부입니다. 도구는 계속 바뀌지만 워크플로 설계 원칙은 유지됩니다.
저도 처음에는 검수 한 번에 한나절을 썼지만, 위 워크플로를 정착시키고 나서 같은 분량을 2시간 안에 끝낼 수 있게 됐습니다. 약 75%의 시간 절감입니다. 도구 선택보다 워크플로 설계가 효과가 크다는 점, 직접 운영하면서 가장 확실히 느낀 부분입니다.
📎 참고하면 좋은 자료
답글 남기기